
В этой заметку покажу, как можно скейлить (масштабировать) кластер k8s - горизонтально, за счет добавления новый нод в кластер.
Если нам требуется добавить новую worker-ноду, то в kubespray имеется отдельный плейбук - scale.yml. Перед его запуском нам требуется только добавить новую ноду в текущий инвентарь.
Для добавления новых мастер нод, ноды также нужно определить в инвентаре и далее запустить основной playbook kubespray.
Я подготовил небольшой кластер состоящий из трех сервером. На базе этого кластера будет реализовывать задачу скейлинга нод.
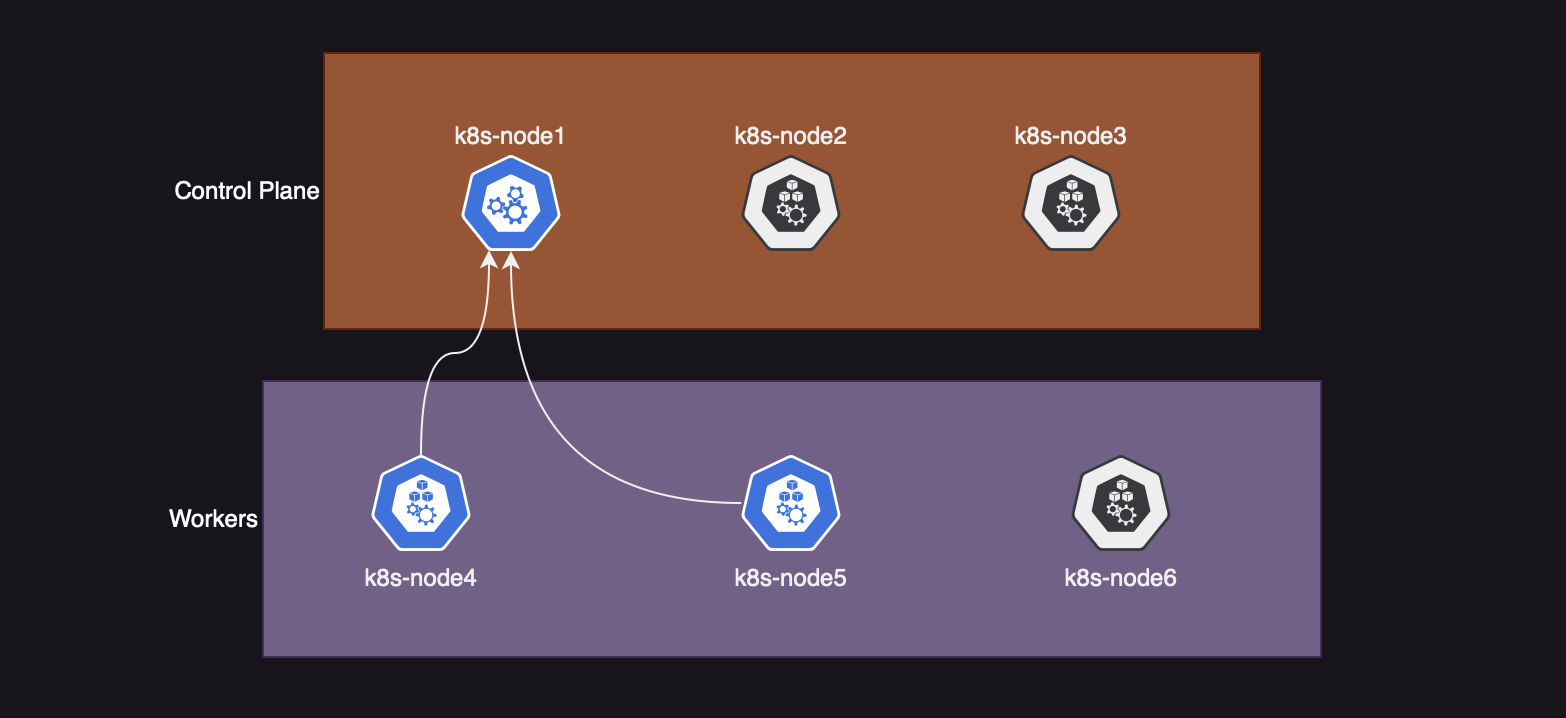 (Серым цветом отображены ноды, которые добавим в процессе)
(Серым цветом отображены ноды, которые добавим в процессе)
Добавление worker-ноды
Начнем с самого простого, добавления новой воркер ноды. Предварительно для этого, я поднял аналогичный по железу сервер и выполнил предподготовительный этап перед добавлением в кластер.
Что касается предготовительных работ, нужно сделать:
- Отключить фаервол (
systemctl disable --now firewalld), - Отключить swap-раздел (
swapoff /path/to/disk), - Обновлить версию ядра на версию выше 4.20,
- Разрешить форвардинг сетевого трафика (
net.ipv4.ip_forward=1), - Ну и добавить ssh-ключ.
Процесс подготовки серверов подробнее описан в заметке по установке кластера через kubespray.
В тот же файл инвентори, с которого поднимали кластер добавляем новую ноду:
[root@k8s-admin kubespray]# vim inventory/k8s-dev-cluster/inventory.ini
---
[all]
k8s-node1 ansible_host=10.200.70.11 ip=10.200.70.11
k8s-node4 ansible_host=10.200.70.14 ip=10.200.70.14
k8s-node5 ansible_host=10.200.70.15 ip=10.200.70.15
k8s-node6 ansible_host=10.200.70.16 ip=10.200.70.16 # <-- Добавил новую ноду
[kube_control_plane]
k8s-node1
[etcd]
k8s-node1
[kube_node]
k8s-node4
k8s-node5
k8s-node6 # <-- И добавил тут
[k8s_cluster:children]
kube_control_plane
kube_node
В файле инвенторя, в конец контекста all добавляем новую ноду - k8s-node6 и указываем адрес ноды. Далее в контексте kube_node также добавляем имя новой ноды - k8s-node6. Сохраняемся и выходим..
Теперь просто запускаем плейбук scale.yml, в течении 10-15 минут новая нода будет добалена в кластер.
[root@k8s-admin kubespray]# ansible-playbook playbooks/scale.yml -i inventory/k8s-dev-cluster/inventory.ini -u root
По завершению сценария выполняем листинг нод в кластера:
[root@k8s-node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready control-plane 2d v1.26.6
k8s-node4 Ready <none> 46h v1.26.6
k8s-node5 Ready <none> 46h v1.26.6
k8s-node6 Ready <none> 2m55s v1.26.6
Как видно из вывода, нода k8s-node6 была поднята почти 3 минуты назад.
На обновленной схеме, состав кластера будет таким:
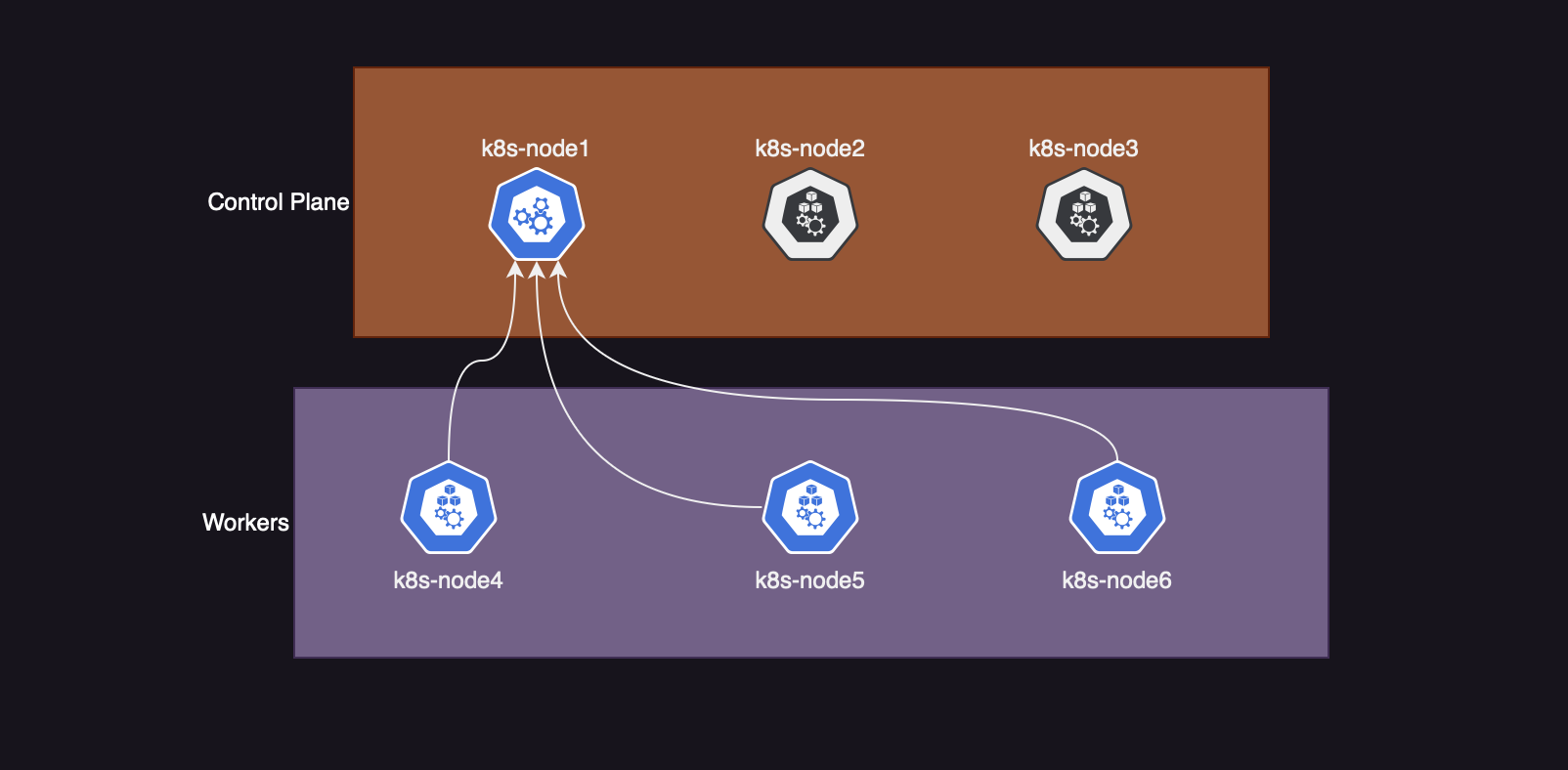
Добавление нод в Control Plane
Для решения данной задачи, я также подготовил и настроил два сервера - k8s-node2, k8s-node3.
Обновим файл инвенторя, добавив новые сервера:
[root@k8s-admin kubespray]# vim inventory/k8s-dev-cluster/inventory.ini
---
[all]
k8s-node1 ansible_host=10.200.70.11 ip=10.200.70.11
k8s-node2 ansible_host=10.200.70.12 ip=10.200.70.12 # <-- Второй сервер
k8s-node3 ansible_host=10.200.70.13 ip=10.200.70.13 # <-- Третий сервер
k8s-node4 ansible_host=10.200.70.14 ip=10.200.70.14
k8s-node5 ansible_host=10.200.70.15 ip=10.200.70.15
k8s-node6 ansible_host=10.200.70.16 ip=10.200.70.16
[kube_control_plane]
k8s-node1
k8s-node2 # <-- Определяем тут
k8s-node3 # <-- И тут
[etcd]
k8s-node1
[kube_node]
k8s-node2
k8s-node3
k8s-node4
[k8s_cluster:children]
kube_control_plane
kube_node
В контексте all нашего инвенторя добавляем сервера и указываем их ip-адреса. Далее в группу инвентаря kube_control_plane прописываем ноды - k8s-node2/3, для установки компонентов control plane.
Как я и говорил, для запуска процесса добавления control plane нод нужно запустить основной плейбук. Процесс перенастройки control plane области займет 10-15 минут. При этом я тестировал работу кластера и он был доступен. Но в продакшене не рекомендую этого делать, так как нет понимания как эта черная коробка сможет себя повести. Поэтому всегда прогоняйте тесты.
Скейлинг control plane запускаем командой:
[root@k8s-admin kubespray]# ansible-playbook -i inventory/k8s-dev-cluster/inventory.ini -u root cluster.yml
Выполнив вывод всех нод, будет такая картина:
[root@k8s-node1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready control-plane 74m v1.26.6
k8s-node2 Ready control-plane 5m21s v1.26.6
k8s-node3 Ready control-plane 5m3s v1.26.6
k8s-node4 Ready <none> 72m v1.26.6
k8s-node5 Ready <none> 72m v1.26.6
k8s-node6 Ready <none> 43m v1.26.6
Также отразиться и на схеме:
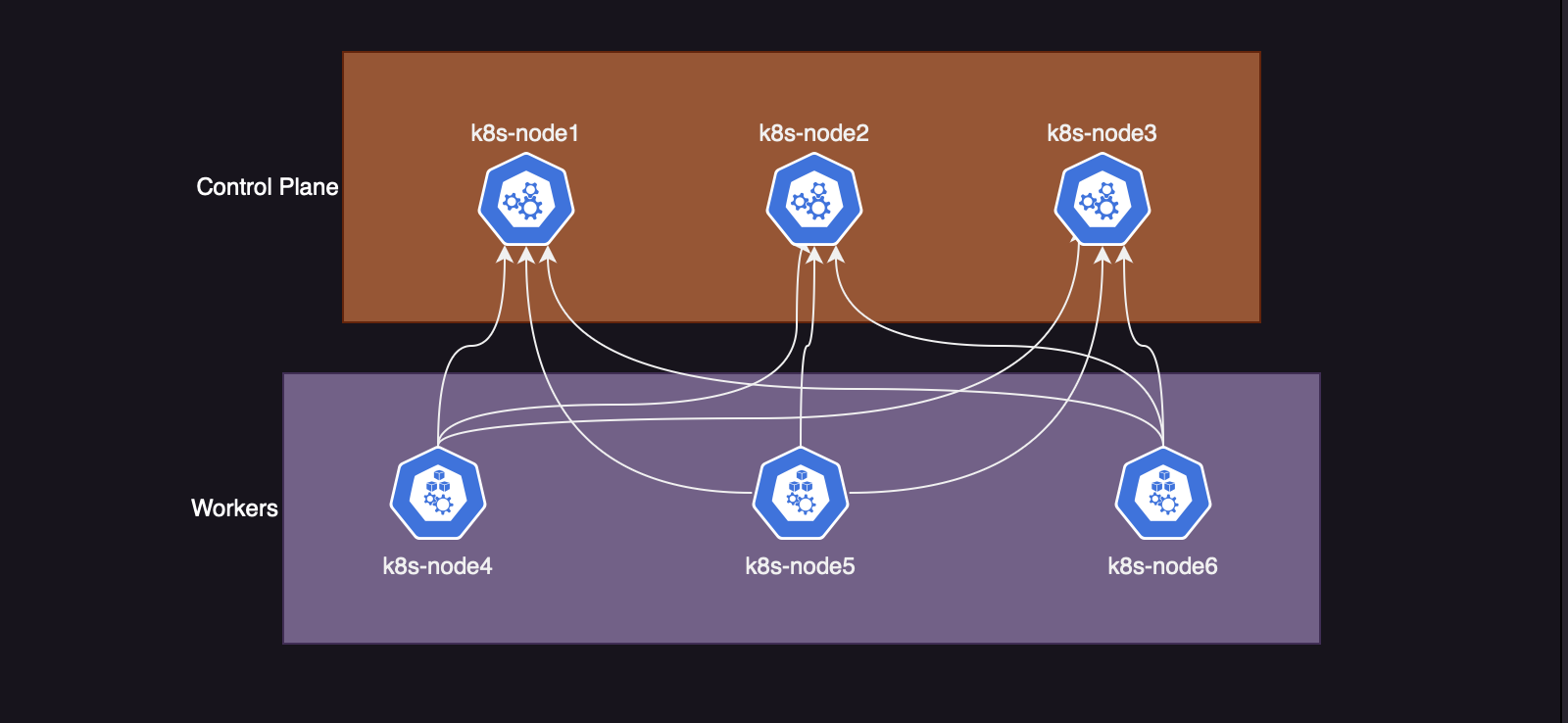
Стоит отметить один нюанс, etcd остался также только на одной ноде. И в случаи падения первой ноды, на которой крутить единственный экземпляр etcd, кластер развалится.
Скейлим Etcd
В прошлый итерациях я пробовал скейлить control plane вместе с etcd, и все ломалось каждый раз. Попробуей добавить сразу два экземпляра etcd, при условии что control plane область размазана на три сервера.
Открываем инвентарь и редактируем его:
[all]
k8s-node1 ansible_host=10.200.70.11 ip=10.200.70.11
k8s-node2 ansible_host=10.200.70.12 ip=10.200.70.12
k8s-node3 ansible_host=10.200.70.13 ip=10.200.70.13
k8s-node4 ansible_host=10.200.70.14 ip=10.200.70.14
k8s-node5 ansible_host=10.200.70.15 ip=10.200.70.15
k8s-node6 ansible_host=10.200.70.16 ip=10.200.70.16
[kube_control_plane]
k8s-node1
k8s-node2
k8s-node3
[etcd]
k8s-node1
k8s-node2 # <-- Добавил тут
k8s-node3 # <-- И тут
[kube_node]
k8s-node4
k8s-node5
k8s-node6
[k8s_cluster:children]
kube_control_plane
kube_node
В группу etcd наверное инвентори добавим новые хосты.
Сохраняем инвентори файл, и запускаем основной плейбук используя опции:
[root@k8s-admin kubespray]# ansible-playbook -i inventory/k8s-dev-cluster/inventory.ini -u root cluster.yml --limit=etcd,kube_control_plane -e ignore_assert_errors=yes -e etcd_retries=10
Опция --limit ограничивает область воспроизведения ansible плейбука. В нашем случаи мы говорим ансибл, проиграть плейбук на группах хостов - etcd, kube_control_plane.
Далее идут аргументы передающие так называемые extra_vars. Переменная ignore_assert_errors включаем игнорирование ошибок утверждения. А переменная etcd_retries передает количество попыток повторных подключений между узлами etcd.
По завершению установки подключаемся на любую мастер-ноду и смотрим состояние etcd кластера, командой:
[root@k8s-node1 ~]# etcdctl --cluster=true endpoint health --endpoints=https://10.200.70.11:2379,https://10.200.70.12:2379,https://10.200.70.13:2379 --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/node-k8s-node1.pem --key=/etc/ssl/etcd/ssl/node-k8s-node1-key.pem
--
https://10.200.70.12:2379 is healthy: successfully committed proposal: took = 13.890261ms
https://10.200.70.13:2379 is healthy: successfully committed proposal: took = 13.991051ms
https://10.200.70.11:2379 is healthy: successfully committed proposal: took = 21.819278ms
В качестве агрументов передаем адреса всех трех эндпоинтов etcd, далее рутовый сертификат кластера и сертификат/ключ нод.
Сертификаты и конечные точки можно посмотреть в манифесте api-сервера тут:
[root@k8s-node1 ~]# grep "etcd-" /etc/kubernetes/manifests/kube-apiserver.yaml
- --etcd-cafile=/etc/ssl/etcd/ssl/ca.pem
- --etcd-certfile=/etc/ssl/etcd/ssl/node-k8s-node1.pem
- --etcd-keyfile=/etc/ssl/etcd/ssl/node-k8s-node1-key.pem
- --etcd-servers=https://10.200.70.11:2379,https://10.200.70.12:2379,https://10.200.70.13:2379
Отлично, вот так мы попробовали проскейлить все важные компоненты кластера. Из полезных ссылок прикладываю документацию к kubespray в github: